
Have you ever found yourself staring at your Kubernetes dashboard watching costs climb while your Java background jobs crawl along? We’ve all been there, stuck with inefficient resource allocation as our batch processing jobs pile up and deadlines loom.
But what if you could dynamically scale your Java workloads based on actual job demand instead of arbitrary CPU thresholds?
In JobRunr 8 we are introducing the JobRunr Pro metrics API that will help you do exactly that. Let’s explore how this could work.
The Background Job Scaling Problem
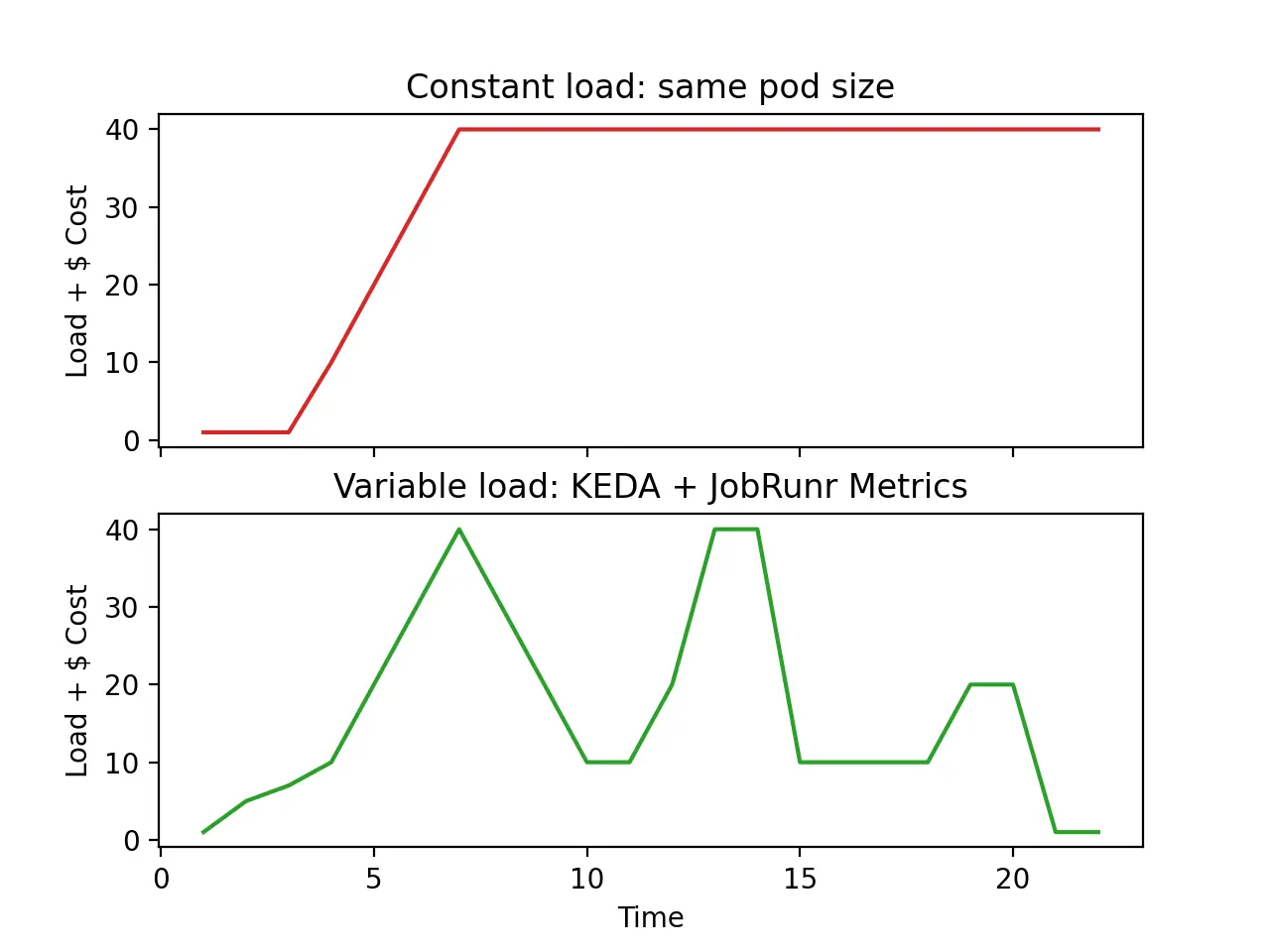
Traditional autoscaling approaches rely heavily on CPU or memory metrics, which are poor proxies for what really matters in background job processing: your actual workload. This disconnect leads to all-too-common scenarios:
- Over-provisioning (usually in vertical scaling scenarios): paying for idle resources “just in case” jobs come in.
- Under-provisioning (usually in horizontal scaling scenarios): scaling too late, only after bottlenecks and delays have already impacted users.
- Slow response to changing workloads: scaling up only after users are already experiencing delays.
The result? A combination of unpredictable performance and unnecessary costs. Vertical scaling leaves you with expensive, underutilized infrastructure, while horizontal scaling reacts too late to protect user experience.
Using JobRunr Metrics for intelligent scaling
JobRunr Pro provides specialized metrics that can help make smart decisions to automatically spin up or take down Kubernetes pods based on:
- Workers’ usage: Measures how busy your job-processing workers are. If workers are consistently near full utilization, the system can scale out to avoid slowdowns and ensure jobs are processed without delay.
- Job queue latency: Tracks how long jobs are waiting in the queue. If jobs are waiting too long before being picked up, it signals that more processing power is needed to clear the backlog.
- Scheduled jobs count: Looks ahead at how many jobs are about to run in the near future. This allows the system to proactively scale up before those jobs start, preventing queues from building up in the first place.
When combined with Kubernetes Event-Driven Autoscaler (KEDA), these metrics create a responsive system that scales precisely when needed — no more, no less.
Why this matters: A Real-World Example
Consider a financial services company processing transactions. During peak hours, their payment validation jobs would pile up, creating a backlog that delayed confirmations to customers. Using traditional CPU-based scaling, the system would only respond after experiencing significant slowdown.
By leveraging the new JobRunr metrics API in combination with the KEDA autoscaling feature, they were able to:
- Scale to 0 during quiet periods to save costs
- Proactively scale up before scheduled batch jobs to reduce latency
- Maintain consistent job processing times even during unexpected traffic spikes
How It Works in Practice

Let’s see this in action with a real example:
Starting state: No jobs, so KEDA scales to 0 workers (saving costs)
40 jobs scheduled: The scheduled jobs trigger spins up 5 worker pods. In the configuration file, we defined a target value of 8 jobs per pod. (40 jobs ÷ 8 jobs per pod = 5 pods). This autoscaling is initiated by the Scheduled Jobs Trigger
Processing begins: As jobs run, worker utilization hits 100%
Scale for utilization: After 30 seconds, KEDA detects high worker usage and adds more pods. This happens automatically because the Workers’ Usage Trigger is activated.
Job completion: After all jobs finish and the cooldown period expires, KEDA scales back to 0
Now your resources are perfectly matched to workload demands, optimizing both performance and cost.
Performance Impact: The numbers
In our testing, properly configured JobRunr metrics-based autoscaling delivered impressive results:
- Our v8 testers experienced a 869% speed increase when scaling from 1 to 10 instances. The autoscalling is done before a delay in performance is noticed.
- Consistent job processing times regardless of workload fluctuations.
- 40-60% cost reduction compared to static provisioning.
Want to dive deeper?
If you want to implement this in your own environment, we’ve prepared a detailed guide to help you get started. In this guide, you’ll learn how to connect JobRunr’s metrics API with KEDA and set up intelligent, workload-based scaling. We also cover example configurations and best practices to fine-tune scaling for your specific use case.